AI
What you need to know about CUDA to get things done on Nvidia GPUs


Understanding a few things about the NVIDIA ecosystem can help you grok some impenetrable stack traces and save you from unnecessary headaches. Let’s break it down and go over some common terms and concepts that come up in your development experience when working with GPUs. This is written for devs and data scientists using high-level libraries like Pytorch, TensorFlow, or JAX.
The Plug
Checkout brev.dev for ready-to-use GPUs for dev, training, and inference. No NVIDIA knowledge required!
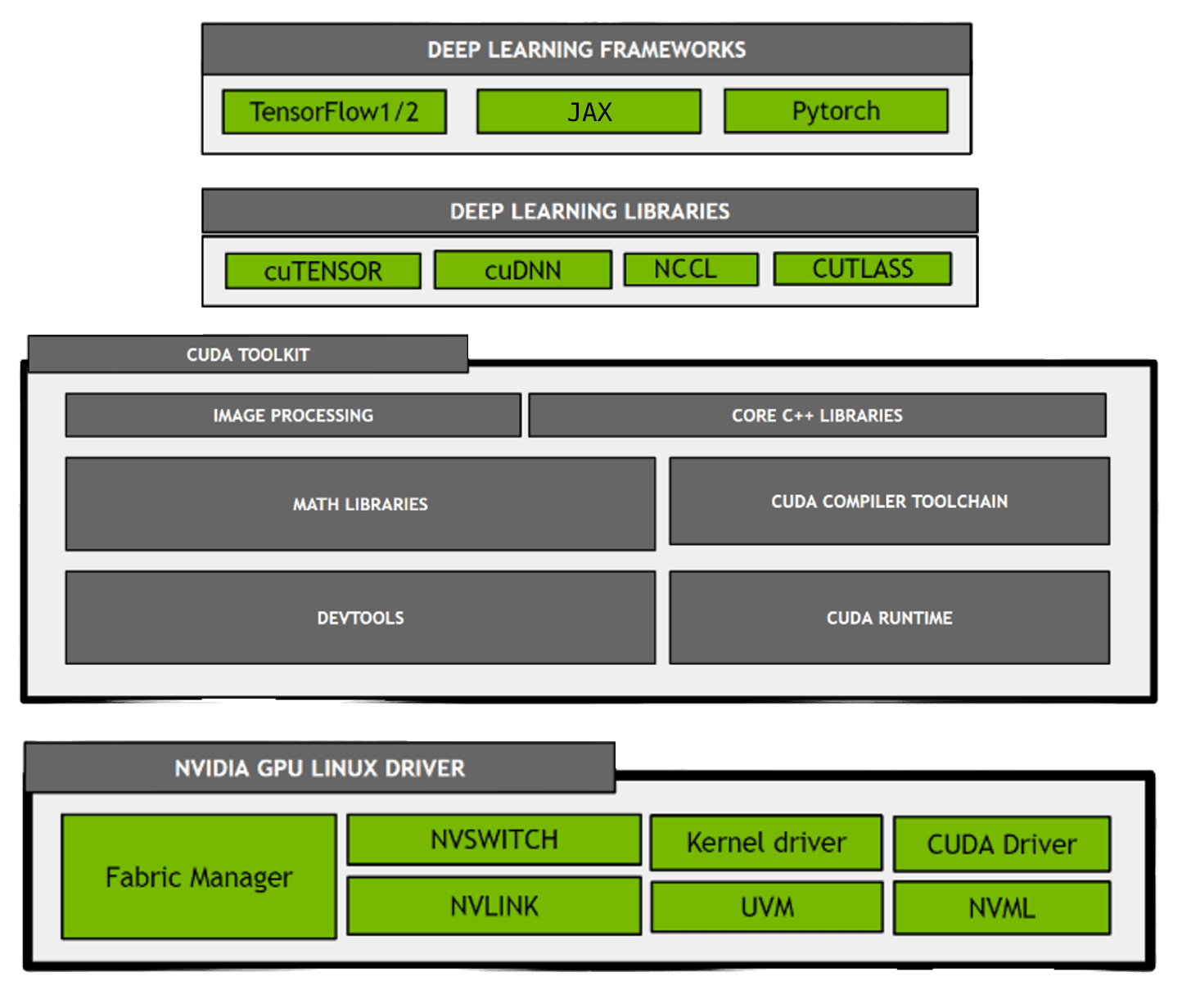
What is NVIDIA CUDA?
CUDA is the high-level name for NVIDIA’s parallel computing platform, consisting of runtime kernels, device drivers, libraries, developer tools, and APIs. This family of software allows developers to use CUDA-enabled GPUs, dramatically speeding up applications, such as those powered by neural networks. “CUDA” also can refer to the code written to take advantage of NVIDIA GPUs, commonly done in C++ and Python.
Help improve this article
This article is a work in progress; help me improve it by joining our Discord.
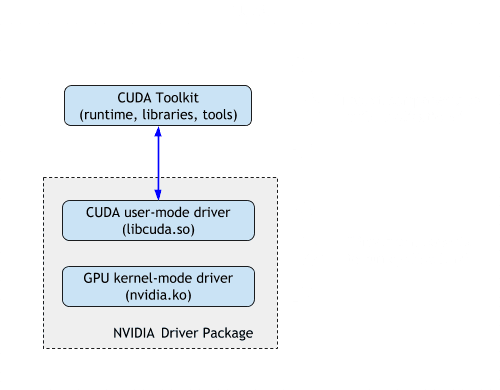
CUDA Toolkit
The CUDA Toolkit (CTK) is a set of tools and libraries that allow programmers to build, debug, and profile GPU-accelerated applications. It includes several notable binaries, like the CUDA runtime and NVCC compiler. CUDA Toolkit and their libraries have version numbers like 11.x, 12.x, etc. As of this article's last update on September 18th, 2023, the latest CUDA Toolkit version is 12.2. When possible, avoid installing multiple different releases of CUDA drivers and runtime software. There are some exceptions, like when using containers.
Relevant Environment Variables
$CUDA_HOMEis a path to the system CUDA and looks like/usr/local/cuda, which may link to a specific version/usr/local/cuda-X.X.$LD_LIBRARY_PATHis a variable to help applications find linked libraries. You may want to include a path to$CUDA_HOME/lib.$PATHshould include a path to$CUDA_HOME/bin.
CUDA Runtime (cudart)
The CUDA runtime is the interface through which software can access CUDA's capabilities. It's a library that handles tasks like device management, memory allocation, and the execution of kernels. You’ll find this library named libcudart.so. Pytorch and TensorFlow use this library to push their computation onto the GPUs.
A CUDA kernel is a function that is executed on the GPU
CUDA NVCC
This is the main tool for compiling CUDA code. It transforms CUDA code into formats (kernels) that can be understood and executed by the runtime on the GPU. This library is required when building TensorFlow or Pytorch from source.
NVIDIA Drivers
NVIDIA drivers provide the low-level functionality that CUDA runtime relies on. They have several responsibilities, including:
- Device/Power management: NVIDIA drivers manage the available GPUs on the system and provide CUDA runtime with information about each GPU, such as its memory size, clock speed, and number of cores.
- Memory management: NVIDIA drivers manage the memory on the GPUs and provide CUDA runtime with access to this memory.
- Scheduling: NVIDIA drivers schedule the execution of CUDA kernels on the GPUs.
- Communication: NVIDIA drivers provide CUDA runtime with the ability to communicate between the host CPU and the GPUs.
Drivers have versions that look like 4xx.xx or 5xx.xx. They are sometimes referred to by their branch, which looks like R4xx or R5xx.
NVIDIA drivers are backward compatible with GPUs, but legacy GPUs have a maximum supported driver. The CUDA Toolkit/runtime has a minimum driver version and generally can use newer NVIDIA drivers. Driver R450 and older are end-of-life, and the R470 will be end-of-life in 2024; however, some GPUs may still be supported through NVIDIAs “Legacy GPU” drivers.
Install the newest possible NVIDIA driver when possible.
CUDA Tookit 11 requires driver ≥ 450 and CUDA Toolkit 12 requires ≥ R525
If you have an older NVIDIA driver and you need to use a newer CUDA Toolkit, you can use the CUDA forward compatibility packages that NVIDIA provides. This is useful when you cannot update the NVIDIA driver easily, for example on a cluster, but need to use a new version of CUDA that Pytorch or TensorFlow require.
CUDA Compute Capabilities and Microarchitectures
NVIDIA uses CUDA GPU compute capability versions to numerically represent hardware features. These features include new data types, tensor cores, and other specifications. The capability numbers range from 1.0-9.0.
Microarchitectures are branded names (Hopper, Ampere, Turing) for GPUs that correlate to certain ranges of compute capabilities. For example, compute capability 7.5 correlates to microarchitecture Turing and capability 8.0-8.7 is microarchitecture Ampere.
Different GPUs will have a compute capability number associated with it. For example, the A100 has the compute capability 8.
Different compute capabilities support different CUDA Toolkit versions. For example, the latest capability 9 (Hopper) only supports CUDA 11.8-12.x.
Capability 3.0-3.7 (Kepler) is seen as unsupported by many libraries, since NVIDIA announced that the last supported driver will be R470, which will soon reach end-of-life
NVIDIA Deep Learning Libraries
NCCL
NCCL (NVIDIA Collective Communications Library) is a library for implementing multi-GPU and multi-node collective communication operations. It is used to enable efficient distributed training of deep learning models across multiple GPUs. Pytorch and TensorFlow both leverage NCCL for distributed training.
cuDNN
The CUDA Deep Neural Network library (cuDNN) is a GPU-accelerated library for deep neural networks. It provides optimized primitives for functions frequently used in deep learning. Pytorch and TensorFlow automatically use cuDNN under the hood.
Deep Learning Frameworks
Pytorch and CUDA
The Pytorch binaries come with their own versions of CUDA runtime, cuDNN, NCCL, and other NVIDIA libraries. You don't need to have the CUDA Toolkit installed locally to run Pytorch code, only a compatible NVIDIA driver. Different versions of Pytorch come with different CUDA versions. However, if you build Pytorch from source code or create custom CUDA extensions, it will use your locally installed CUDA Toolkit.
TensorFlow and CUDA
TensorFlow, on the other hand, does not come with its own CUDA Toolkit and cuDNN. These must be installed separately along with compatible NVIDIA drivers. Specific versions of TensorFlow require specific releases of the CUDA Toolkit and cuDNN.
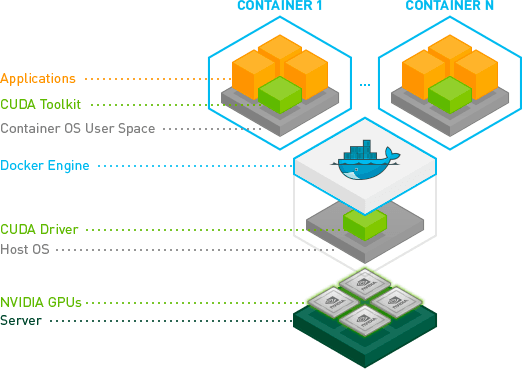
Containers and CUDA
Using virtual containers are a great way to increase the portability of your software. Containers can use GPUs by installing a specific CUDA Toolkit in the container, and installing the NVIDIA Container Toolkit and the NVIDIA drivers on the host machine. Drivers can alternatively be installed via a container using NVIDIA Driver Containers to increase reproducibility and decrease installation times. If you're interested in more details, check out the NVIDIA container stack architecture overview.
Conclusion
Understanding a bit of NVIDIA’s ecosystem can go a long way when working with GPUs. In this guide, we covered what I think are important concepts I wish I'd known when debugging NVIDIA bugs and stack traces. Join our Discord to give feedback and discuss other quirks and features you’ve run into when using NVIDIA’s toolchain!
Want NVIDIA drivers, CUDA toolkit, Container Toolkit, and environment variables to be configured correctly and work every time? Check out brev.dev for ready-to-use cloud GPUs.